【R】Spotify APIを利用して関連するアーティストをDigりまくる
今回は、Spotify APIを利用してデジタルにdigをしてみます。目次は以下の通りです。
はじめに
先日、「SpotifyのAPI利用をRでできねーかなー」とか思っていたら、まさにドンピシャのパッケージ {spotifyr} を発見しました。
(Pythonには{spotipy}ならぬ同じようなパッケージが存在しますが、それに比べてこのパッケージのネーミング微妙じゃね?と思いました。)
何をするのか
ともあれ、今回はこのRパッケージを使って「関連するアーティスト」のネットワークを可視化する作業をやってみたいと思います。上手く可視化できれば何千もの関連するアーティストを一気にDigれるので、音楽オタクの皆様にはとても最適な内容です。
パッケージの読み込み+α
まずは、作成者であるcharlie86氏のGitHubページに倣ってパッケージをインストールしましょう。私の確認では、このパッケージはCRAN上にないので、GitHub上からでしかインストールできないっぽいです。
devtools::install_github("charlie86/spotifyr")
次にパッケージを読み込みます。今回使用するパッケージは以下の通りです。
library(tidyverse) # 実家のような安心感 library(spotifyr) # 今回のメイン library(igraph) # ネットワーク分析で重宝するパッケージ library(tidygraph) # グラフデータをtidyに library(ggraph) # ggplot2でグラフ
また、SpotifyのAPIを利用するためにはdeveloper登録をする必要がありますので事前に済ませておいてください。登録は以下のブログが参考になると思います。
登録が完了したらClient IDとClient Secretを確認します。それらをRに以下のように貼り付けてください。
Sys.setenv(SPOTIFY_CLIENT_ID = "Your client ID") Sys.setenv(SPOTIFY_CLIENT_SECRET = "Your client secret")
アーティスト情報の取得
次に、今回の肝である関連するアーティスト情報の取得を行っていきましょう。
まずは、起点となる最初のアーティストの情報を取得していきます。これは別に何でもいいのですが、最近小中学生の時にドハマりしていた音楽ブームが個人的に巻き起こっているのでとりあえず ``My Chemical Romance"でやってみます。ちなみに、マイケミで一番好きな曲はDisenchantedです。
それでは早速やっていきましょう。
まずは、マイケミのSpotify上でのIDを取得していきます。search_spotify関数で該当するアーティスト情報を抜き出します。
search <- search_spotify("my chemical romance") id <- search$artists$items$id[1] # 有名なアーティストならばid変数のの1要素目 artist_name <- search$artists$items$name[1] # 後で使うので一応名前も抜く
次にget_related_artists関数で「関連するアーティスト」を抜き出していきます。デフォルトだと最大で20組が抜き出されます。
related <- get_related_artists(id) related_name <- related$name # 名前を抜く related_id <- related$id # IDを抜く related_name
[1] "The Used" "The Red Jumpsuit Apparatus" "Yellowcard" [4] "Hawthorne Heights" "The All-American Rejects" "Good Charlotte" [7] "Frank Iero" "All Time Low" "Mayday Parade" [10] "Simple Plan" "Senses Fail" "Escape the Fate" [13] "AFI" "Fall Out Boy" "Jimmy Eat World" [16] "Silverstein" "Falling In Reverse" "Panic! At The Disco" [19] "Pierce The Veil" "Angels & Airwaves"
P!ATDやThe Usedなど当時のアーティストの中にPierce The VeilやFalling In Reverseなんかが紛れ込んでいるんですね。先日、PTVのKing for a dayのMVを超久しぶりに見たら再生数1億回超えてて狂ってましたね。懐かしすぎて中1の頃が偲ばれます。あと実はKellin Quinnってもう35歳らしいですよ。年齢不詳だな~。
話題が完全にそれてしまいましたが、今抜き出した値を「検索アーティスト」「関連するアーティスト」に対応するようにデータフレームに格納します。
data <- tibble(artist_name, related_name) data_id <- tibble(artist_name, related_id) head(data)
# A tibble: 6 x 2 artist_name related_name <chr> <chr> 1 My Chemical Romance The Used 2 My Chemical Romance The Red Jumpsuit Apparatus 3 My Chemical Romance Yellowcard 4 My Chemical Romance Hawthorne Heights 5 My Chemical Romance The All-American Rejects 6 My Chemical Romance Good Charlotte
それでは、早速「関連するアーティスト」の「関連するアーティスト」を抜き出してみましょう。まずは、分析しやすくするためにsearch_relate関数を定義します。
search_related <- function(id) { artist <- get_artist(id) artist_name <- artist$name related <- get_related_artists(id) related_name <- related$name related_id <- related$id data <- tibble(artist_name, related_name) data_id <- tibble(artist_name, related_id) return(list(data = data, data_id= data_id, related_id = related_id)) }
検索IDを入れれば、勝手に「検索アーティスト」「関連するアーティスト」のデータフレームと「検索ID」「関連ID」データフレーム、さらに「関連ID」ベクトルを含むリストを返してくれます。
次にこの関数をマイケミの関連するアーティスト20組にそれぞれ適用し、新たに202 = 400組を抜き出してみます。正直、for文だと遅いのでmapで処理したかったところですが、なぜかmapだと上手く取得しきれなかったので仕方なくfor文で行きます。これを実行すれば、一番最初に作成した「マイケミ」「関連するアーティスト」データフレームにどんどん新たにアーティストが追加されていきます。
今回は、あまりデータが莫大になりすぎると大変なので、3回の繰り返しだけにします(つまりマイケミの「関連するアーティスト」の「関連するアーティスト」の「関連するアーティスト」の「関連するアーティスト」まで)。
# 1回目 for (i in 1:length(related_id)) { out <- search_related(related_id[i]) if (exists("df_relate") == TRUE) { df_relate <- bind_rows(df_relate, out$data) } else{ df_relate <- bind_rows(data, out$data) } if (exists("df_relate_id") == TRUE) { df_relate_id <- bind_rows(df_relate_id, out$data_id) } else{ df_relate_id <- bind_rows(data_id, out$data_id) } } # ここで重複ペアを消す df_relate_id_2 <- df_relate_id[-(1:20), ] %>% mutate(pair = paste0(artist_name, related_id)) %>% distinct(pair, .keep_all = TRUE) %>% select(-pair) # 2回目 for (i in 1:nrow(df_relate_id_adj)) { out <- search_related(df_relate_id_adj[i, 2]) if (exists("df_relate2") == TRUE) { df_relate_2 <- bind_rows(df_relate_2, out$data) } else{ df_relate_2 <- bind_rows(df_relate, out$data) } if (exists("df_relate_id_2") == TRUE) { df_relate_id_2 <- bind_rows(df_relate_id_2, out$data_id) } else{ df_relate_id_2 <- bind_rows(df_relate_id, out$data_id) } } # 前の420組のペアリスト削除したいので、まずはリストを作る pair_list <- df_relate_id %>% mutate(pair = paste0(artist_name, related_id)) %>% select(pair) %>% as.matrix() %>% as.character() # filter関数では複数のマッチに対して補集合を返すものがない(というか知らない)ので定義する `%notin%` <- Negate(`%in%`) # 削除 df_relate_id_2_adj <- df_relate_id_2[-c(1:420), ] %>% mutate(pair = paste0(artist_name, related_id)) %>% filter(pair %notin% pair_list) %>% distinct(pair, .keep_all = TRUE) %>% select(-pair) # 3回目 for (i in 1:nrow(df_relate_id_2_adj)) { out <- search_related(df_relate_id_2_adj[i, 2]) if (exists("df_relate_3") == TRUE) { df_relate_3 <- bind_rows(df_relate_3, out$data) } else{ df_relate_3 <- bind_rows(df_relate_2, out$data) } if (exists("df_relate_id_3") == TRUE) { df_relate_id_3 <- bind_rows(df_relate_id_3, out$data_id) } else{ df_relate_id_3 <- bind_rows(df_relate_id_2, out$data_id) } } # さいごに重複を削除 df_relate_3 %>% mutate(pair = paste0(artist_name, related_name)) %>% distinct(pair, .keep_all = TRUE) %>% select(-pair) -> df_net df_relate_id_3 %>% mutate(pair = paste0(artist_name, related_id)) %>% distinct(pair, .keep_all = TRUE) %>% select(-pair) -> df_id_net # 一応保存 write.csv(df_relate_3, "relate_name.csv", row.names = FALSE) write.csv(df_relate_id_3, "relate_id.csv", row.names = FALSE)
脳筋的に抽出を繰り返してしまいましたが、あまりよろしくない実行だと思います。もっといいやり方を見つけて改定したいです。
ともあれ、無事に抜き出し終わりました。データを確認してみましょう。
length(unique(df_net$artist_name))
[1] 557
length(unique(df_net$relate_name))
[1] 2100
まあまあの数のアーティストを取得することができました。可視化したらどうなるやら。
ネットワークの可視化
本題に移ります。まずは、先ほどのdf_netをグラフ用(igraphオブジェクト)に変換します。
g <- graph.data.frame(df_net, direct = FALSE) # dataframe → graph data g <- simplify(g, remove.multiple = TRUE, remove.loops = TRUE) # 重複や自己ループを削除 g_tbl <- as_tbl_graph(g, directed = FALSE) # tidyに
それでは、{ggraph}パッケージを用いてネットワークを可視化します。
g_tbl %>% ggraph(layout = "kk") + geom_edge_link(alpha = .6, color = "black", width = .01) + geom_node_point(size = .001, alpha = .5) + geom_node_text(aes(label = name), size = .4, nudge_y = .26) + theme_minimal() + scale_x_continuous(breaks = NULL) + scale_y_continuous(breaks = NULL) + xlab("") + ylab("")

なんだか面白そうなグラフになりました。何がどうなっているのか全く分かりませんが。一番密集しているところを見てみましょう。

何やら2000年代前期に流行ったemoメンツが勢ぞろいですね。
少し外れたところを見てみると、LOATHEやVoid of Visionといった流行りのメタルコアバンドなんかも視認できます。
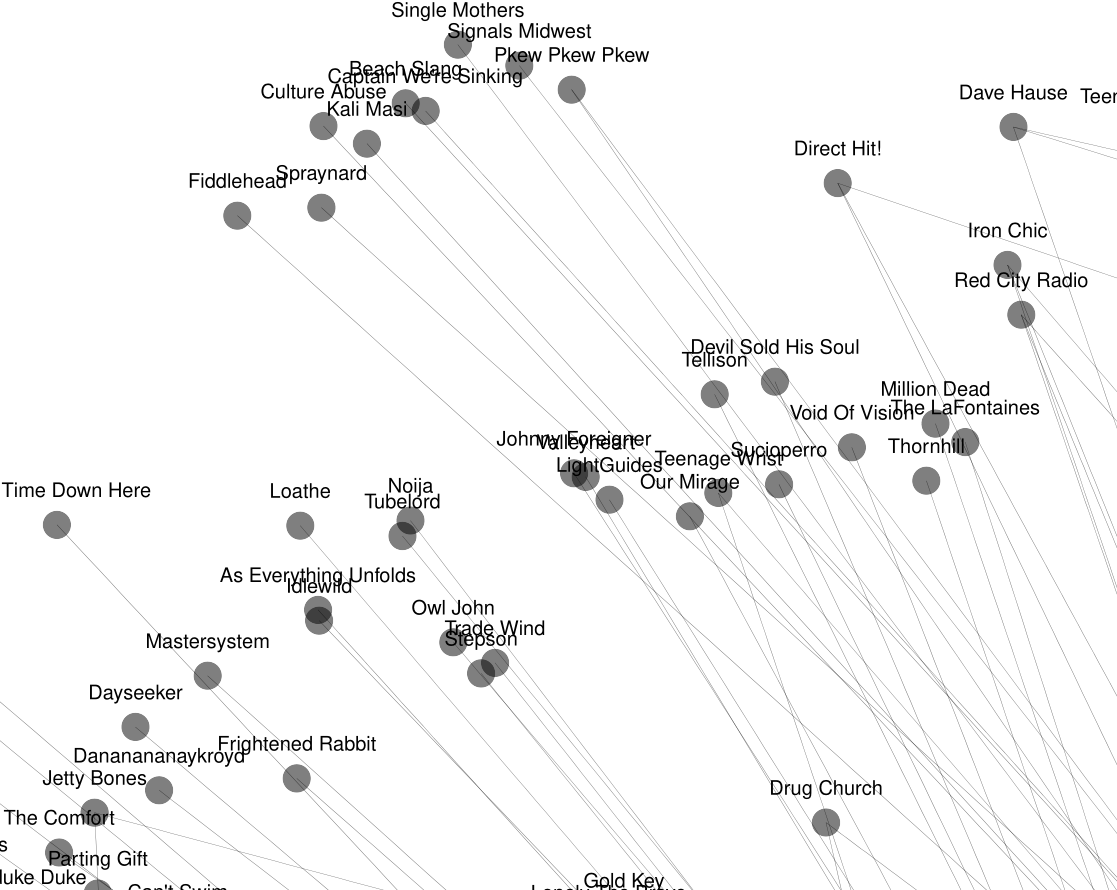
中でも、一番驚いたのがこれ。

なんと末端の方を見ると謎に鬱Pや八王子PなどのボカロPやDECO*27までもいるんです。なんで?マイケミから鬱Pまでの経路を調べてみましょう。
get.shortest.paths(g_tbl, "My Chemical Romance", "Utsu-P")$vpath
[[1]] + 5/2102 vertices, named, from 8f3234d: [1] My Chemical Romance Frank Iero Mindless Self Indulgence Maretu [5] Utsu-P
これ結構衝撃的なのが、Frank Ieroを通ってエレクトロ方面に流れて鬱Pまでたどり着いているようですね。また、ネットワーク分析的Digの醍醐味(?)ですが、新たに ``Mindless Self Indulgence Maretu" というアーティストを知ることができました。あまり好みではなかったですが。
実際のところ、媒介性が一番大きいアーティストを調べてみると
between <- as.matrix(betweenness(g_tbl)) between[which(between == max(between)), ]
Frank Iero
246394.4
Frank Ieroなんですよね。すげー。マイケミからネットワークをスタートさせてマイケミメンバーの媒介力を知るというね。